Terminology
-
Recall that a process is a program in execution. From a scheduling point of view, a process constitutes a claim on the system resources. A process is defined by:
-
A portion of memory that contains the program that is being executed by the process, together with its data.
-
The contents of the CPU registers used by the process (including the PC which determines which instruction in the program is to be executed next.)
-
-
Many other terms have been used historically for what we now call a process. Probably the most common is job - so, to some extent, we will use the terms process and job interchangeably. Another term that occurs frequently is task. (Process is now the preferred term, but much of the nomenclature uses the older term job.)
-
The execution of a process consists of an alternation of CPU bursts and IO bursts. A process begins and ends with a CPU burst. In between, CPU activity is suspended whenever an IO operation is needed.
-
If the CPU bursts are relatively short compared to the IO bursts, then the process is said to be IO bound. (Example: a typical data processing task involves reading a record, some minimal computation, and writing a record.)
-
If the CPU bursts are relatively long compared to the IO bursts, then the process is said to be compute bound. (Example: a typical number crunching task involves an IO burst to read parameters; a very long CPU burst - perhaps hours or more - and another IO burst to write results.)
-
-
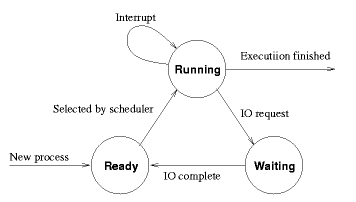
The state of a process: at any given time, a process is in one of several states. While the set of possible states varies from system to system, the following three comprise a minimal set:
-
Running: the CPU is currently executing the code belonging to the process. This means that the hardware CPU registers contain the values associated with the particular process; in particular, the hardware program counter is pointing to code belonging to the process.
-
Ready: the process could be running, but another process has the CPU.
-
Waiting (blocked): before the process can run, some external event (normally the completion of an IO transfer) must occur.
As a process runs, it goes through a series of state transitions, of which the following graph is a simple rendition:
-
Note that, in this model, parallelism between computation and IO is on an inter-process basis: that is, computation for one process overlaps IO for other processes. It is also possible in some systems to have computation and IO for a single process overlap to some extent: a process may start an IO burst and continue computing until it reaches a point where further computation cannot proceed. (e.g. if the operation is a read, computation can proceed until the data read is actually used; if it is a write, computation can proceed until the buffer where the data is stored must be re-used.) If this is the case, then the model must be modified to show the RUNNING -> WAITING transition occurring as the result of an explicit WAIT request by the process, rather than as the automatic result of any IO request.
Ex: VMS SYS$QIOW vs SYS$QIO and SYS$WAIT.
-
Another possibility not shown in the diagram is pre-emption: the scheduler may take the CPU away from a process involuntarily either because it has used up its time quantum or because another, higher priority process needs the CPU. This could be shown in the diagram by a line from RUNNING to READY labelled "pre-emption".
-
-
To manage the various processes, a multiprogrammed system typically uses process control blocks (PCB's). A PCB is a data structure (normally stored in system memory) that records the process's state, registers (unless it is running) and other information such as priority, accounting data etc.
-
Queues: In a multiprogrammed system, there are typically many shared resources: the CPU, disks etc. Since it is possible to have several different processes desiring to use a given shared resource at any time, the scheduler must maintain a queue for each resource.
-
In the context of schedulers, we use the term queue in a broader sense than the way we defined it in Data Structures. An operating system scheduler queue may be managed using a FIFO discipline, but often uses some other ordering mechanism such as some sort of priority scheme.
-
In the case of the CPU, the queue is called the ready list and contains all the ready processes that are not currently running.
-
In addition, queues may be associated with various IO devices that (such as disk) that may be accessed by more than one process at a time.
-
We will defer discussion of scheduling algorithms for these until later.
-
We will also sometimes speak of a queue as being associated with a non-shareable device such as a terminal. Of course, such a queue will contain at most one process.
-
-
Often the PCB's include one or more fields used to maintain the queues. For example, if a FIFO discipline is used, then each PCB might contain a field that can point to the PCB of the process that is next in line, or null if there is none. Note that, at any time, a PCB will be in exactly one queue (possibly at its head, using the resource, or possibly further back waiting on the resource) unless intraprocess overlap of IO and computation is allowed, of course.
-
When the process currently using a shared resource finishes using the resource, the next process in the queue is allowed its turn. In the case of IO devices, this is normally handled by the interrupt handlers - when an interrupt occurs, the current process is returned to the ready list (its IO request is complete) and the IO operation requested by the next process in line is started. In the case of the CPU, a portion of the scheduler called the dispatcher selects a new process for execution whenever the current process yields the CPU.
-
Scheduler goals: schedulers typically attempt to achieve some combination of the following goals. Note that, to some extent, these goals are contradictory - hence what is achieved must be a compromise:
-
Maximize CPU utilization (due to its relatively high cost)
-
Maximize utilization of other resources (disks, printers etc.)
-
Maximize throughput = number of jobs completed per unit time.
-
Minimize waiting time = total time a job spends waiting in the various queues for a resource to become available.
-
Minimize turnaround time = waiting time + computation time + IO time
-
Minimize response time (timesharing) = time from entry of a command until first output starts to appear. (Note that this is the only delay the user perceives, since the slowness of a typical terminal masks most subsequent waiting time unless the system load is very heavy.
-
Fairness - all comparable jobs should be treated equitably.
-
Avoid indefinite postponement.
-
Uniformity - the behavior of the system should be predictable. (e.g. interactive users tend to prefer a response time of several seconds to response times generally very low with occassional long delays.)
-
Graceful degradation - in the face of excessive loads, the system response deteriorates gradually, rather than coming to a sudden virtual standstill.
Types of schedulers: A multiprogrammed system may include as many as three types of scheduler:
-
The long-term (high-level) scheduler admits new processes to the system.
-
Long-term scheduling is necessary because each process requires a portion of the available memory to contain its code and data. Thus, the total size of memory imposes an upper-limit on the multiprogramming level or number of active processes.
-
In a time-shared system, a common approach is to have the management establish an upper limit on the number of users allowed on line. Often this is done by allocating a fixed number of PCB's: when all are in use, no new process can be created. The long term scheduling algorithm is as follows:
whenever a new user attempts to login: if number of processes > maximum then create a new process for the user else tell him to come back later.(A certain amount of long-term scheduling also occurs as users voluntarily leave a heavily loaded system to return later when the usage is less.)
-
In a batch system, a long term scheduler may attempt to achieve a good balance (job mix) between compute-bound and IO bound jobs. Ideally, the job mix would include 1-2 compute bound jobs that can help maximize CPU usage, plus as many IO bound jobs as possible - preferably representing a good mixture of demands on the various shared IO devices.
-
Note that CPU time is wasted whenever the ready list is empty - i.e. all jobs are in the wait state. Compute bound jobs are almost always ready and thus help ensure that little CPU time goes unused.
-
If there are several shared IO devices (e.g. disks), it would be desireable to ensure that the needs of the various IO bound processes are distributed as evenly as possible among them, rather than having all processes competing for a single disk.
-
This kind of scheduling is hard to automate, since it is hard for the operating system to predict what a job will need. System management can also do long-term scheduling by scheduling batch runs throughout the week or month in a way that helps to improve the job mix.
-
-
-
Medium-term (intermediate) scheduling is not found in all systems. The medium-term scheduler, if present, controls the temporary removal from memory of a process when this is expedient. (This is called swapping). The need for swapping may occur in two ways:
-
In a timeshared system, the long-term scheduler may admit more users than can all fit in memory. However, since time-shared jobs are characterized by bursts of activity interspersed with periods of idleness while the user thinks, the medium-term scheduler can swap-out temporarily inactive jobs. As soon as new input arrives from the user, the job can be swapped back in and another job swapped out.
-
In any kind of system, a sudden increase in the memory requirements for one job can make it necessary to either swap out the job that wants to grow until space is available for it or swap out another job to make room for it.
-
Note that the medium-term scheduler only swaps out jobs when it has too. Ideally, swapping should only occur when the usage level on the system is very high. Often, the onset of swapping brings a noticeable decrease in system performance - which may help to reduce the multiprogramming load on a timeshared system as users give up until later.
-
-
The short term scheduler determines the assignment of the CPU to ready processes. Most of our discussion will focus on this kind of scheduling.
-
Summary:
------------------------------------------ | Swapped-out processes | | | |--------------- MT -----------------------| Incoming | Memory-resident | Running | Jobs -----> LT processes ST Process (1) | | (waiting or ready) | | ------------------------------------------ -
Note on frequency of execution:
-
Long-term scheduler is executed infrequently - only when a new job arrives. Thus, it can be fairly sophisticated.
-
Medium-term scheduler (if it exists) is executed more frequently. To minimize overhead, it cannot be too complex.
-
Short-term scheduler is executed very frequently - whenever any IO request occurs, and often when one completes. Thus, it must be very fast. On newer machines, it is common to find hardware support for certain scheduler functions to help out.
-