Strategy for allocating memory:
-
Early systems used blocks of contiguous memory
Early multiprogramming systems built upon approaches developed in the days of one-user systems. A program on a one user system has available to it a contiguous region of memory, usually extending from the end of the monitor region to the physical end of memory. Early multiprogramming systems (and some in use today) emulated this model by giving each process a contiguous region of memory, bounded on either side by the monitor, another process, and/or physical end of memory. There are two principal contiguous allocation schemes:
-
Fixed partitions
memory is divided into several regions of fixed size. Generally, a process runs in a partition that is the best fit to its memory needs, though some internal fragmentation is almost always involved.
An example is IBM MFT (Multiprogramming with a Fixed number of Tasks) which was part of OS/360. The fixed partitions were set up by the operator in the morning and remained the same for the rest of the day.
Example: Three jobs of size 2K, 7K, 20K running on a system with fixed partitions of 4K, 8K, and 24K:
2K job
/////////////////////7K job
/////////////////////20K job
/////////////////////Here "/////////////////////" represents fragmentation: space that is allocated but not used (here 7K out of a total of 36K)
-
Lack of flexibility
The basic problem with this scheme is its lack of flexibility. For example, in the above situation, a job of size 4K might be in the queue. This could fit in the space not needed by the 20K job; but this would not be possible since partitions are fixed.
-
Maximum job size determined by size of largest partition
A related problem: the size of the largest partition determines the size of the largest runnable job. This either means that no unusually large jobs can ever run, or else one very large partition has to be created, most of whose space is unused at most times.
-
-
Variable partitions
each process is given just the memory allocation it needs (or sometimes slightly more). Partitions change location, size, and often even quantity as processes come and go. (Ex: IBM MVT) As processes leave the system, this results in external fragmentation.
Example: The following processes arrive on a 56K system: 8K, 4K, 12K, 6K, 20K. The 4K and 6K processes terminate, leaving three holes (including the unallocated memory at the end) of size 4K, 6K, 4K:
2K process (4K vacated) 12K process (6K vacated)
20K process(6K remaining) Now, suppose a process arrives needing 8K of memory. Observe that it cannot be fit in, even though the total available storage is enough for two such processes.
-
Basic problem is that over time memory will become fragmented into many small unusable units
-
Problem can be overcome by compaction
-
Partial compaction
As a block of storage becomes free, a check is made to see if either or both of its neighbors are free. If so, then the freed block is conjoined to its neighbor(s) to make one large blocks. This can be done fairly simply - especially in a situation like this, where the total number of blocks is relatively small.
Ex: In the above, if the 12K process terminates, we would combine its allocation with its 4K and 6K neighbors, to make one block of 22K instead of three blocks of 4, 6, and 12K.
-
Full compaction
All existing allocations are moved so as to leave all free space in a single large block, typically at one end of memory.
Ex: In the above, we could move storage in use down toward the start of memory to produce:
2K process 12K process
20K process
(16K free)But this is a non-trivial task, due to:
-
Processor time involved in doing the movement.
On many machines, memory would have to be moved word by word, using a loop with as many as four instructions: move the word, increment pointer, test for completion, branch to loop. Some machines have block move instructions that make this faster.
-
Relocation
More serious is the problem of relocation, to be discussed as a separate issue below. Without some form of hardware relocation, this problem makes compaction a virtual impossibility.
-
-
-
-
The basic problem with both of these schemes is that they require all of the memory allocated to a process to be contiguous.
This was unavoidable on older architecture machines; but many newer machines designed for multiprogramming have hardware provisions that facilitate non-physically-contiguous allocation of memory. We will come back to this later under the heading of paging, segmentation, and combinations of segmentation and paging - as well as next time when we discuss virtual memory.
Scheduling strategies: selection of jobs to become memory resident and possibly selection of jobs to be swapped out.
-
Long-term scheduler may consider memory availability
As we discussed a while ago, the long-term scheduler (job scheduler) selects processes to be allowed on the system on the basis of various considerations including external priority and projected utilization of system resources. Memory availability may be an issue for the scheduler to consider. The issue varies slightly depending on the allocation scheme in use.
-
Fixed partitions: associate job queues with memory partitions
Under fixed partitions, it is common to associate a job queue with each partition (or group of identical-size partitions.) A newly arrived job is placed in the queue corresponding to the smallest partition that can hold it. What happens if there are processes waiting for a smaller partition, and a larger partition becomes vacant, with no jobs waiting in its queue?
Ex: The above. Suppose the 24K partition is vacant, but there are jobs waiting in the 4K and/or 8K queues.
-
We could run the smaller job in the larger partition.
True, internal fragmentation would be massive; but the memory wasted would be less than if we left the partition vacant, and CPU utilization and throughput would improve.
-
but... new large jobs wait for smaller jobs
On the other hand, a newly-arrived job awaiting the larger partition would have to wait for the smaller job to clear it. If the smaller job happens to be long running, this could bottle up the larger job without possibility of relief.
-
-
Variable partitions: single job queue
Under variable partitions, there is normally only one job queue. What if the next job in the queue is too big to fit any available partition, but there are smaller jobs behind it that would fit? Do we jump them over the bigger job? This has obvious advantages; but in a heavily loaded situation it is possible that this could lead to indefinite postponement for the larger job as the smaller jobs keep grabbing space as it becomes available, rather than allowing it to accumulate and be compacted to a sufficient size.
-
-
Intermediate scheduler selecting jobs for swapping
There is also the possibility of an intermediate scheduler selecting jobs to be swapped out of memory to make room for others. This is a somewhat costly operation, particularly for large jobs, so it needs to be done with caution.
-
Batch-only systems: may not be worthwhile
On a batch-only system, it may not be worthwhile. The typical candidate for swapping would be a waiting job; but in a batch environment the typical IO wait time is of a magnitude comparable with swap time. However, if there were several compute bound jobs on the system and insufficient IO bound jobs to keep the IO devices busy, it might be better to swap a compute bound job to make room for one or more IO bound jobs. Likewise, if there is no compute bound job available to keep the CPU busy when all other processes are doing IO, it might be good to swap one in.
-
Time-shared system: swapping may be worthwhile
On a time-shared system, swapping might be more profitable, since minutes or even hours can pass between periods of interactive IO activity. Further, swapping may be unavoidable if the total memory requirements of all users desiring to access the system exceeds the memory available. (Note that even if a user is not admitted unless there is memory available, memory requirements can increase as a user moves from, say, just executing the command interpreter to a compilation using a large compiler.) However, as a pragmatic concern, swapping can degrade system performance. Often as system load increases, there is a sharply noticeable performance degradation as the load reaches the point where swapping becomes necessary.
-
Swapping problem: processes waiting for IO
If swapping is done, one problem that must be faced is how to handle processes waiting for IO. Typically, a process requesting IO has specified a buffer in its own memory space as the location to/from which the transfer is to occur. We don't want to have a swapped out user's IO activity taking place to/from the space allocated to the user swapped in in his place.
-
Use system memory for IO buffers
One approach is to do all IO activity to/from buffers located in operating system space.
On a write, the operating system transfers the data from the user's buffer to its own, then it initiates the actual transfer. On a read, when the transfer has been completed (to a system buffer), the operating system transfers the data to the user's buffer.
Of course, this involves added overhead.
-
Don't swap processes waiting for IO
Or, swapping of a process awaiting IO may be forbidden. But this means that an interactive process awaiting user command input that may not come for hours would be locked into memory.
-
Retain part of memory containing buffer
In a paged/segmented system, only the actual page/segment containing the buffer need remain in physical memory.
-
Compromise approach
A compromise approach may be taken - e.g. VMS: disk IO is done to/from buffers in user space, and so requires that the pages containing these buffers be locked until the IO is complete. Terminal IO is done to/from system buffers, with a copy between the system buffer and the user buffer needed. This allows interactive processes to be completely swapped out during potentially long terminal input waits (or output waits if the user pushes No Scroll.)
-
-
Physical location in memory (is it important?)
Another issue with swapping concerns the location in memory to/from which the program is swapped. Must a program always be swapped back into the same memory location it was swapped out of? This is clearly inconvenient (to say the least); but if not, then the program must be relocated to reflect its new "home".
-
Relocation
Any user program contains numerous addresses that refer either to other instructions in the program (e.g. for branches, calls) or to data items. Further, as it runs various pointers to code and data may be created dynamically by such operations as procedure calls (return address => pointer to code; parameters => pointers to data) or dynamic storage allocation as by the Pascal new procedure or the C++ new operator. Obviously, these addresses must reflect in some way the actual location in memory occupied by the program.
-
Absolute code
The earliest translators produced absolute code, that had to be located at a specified address in memory. This was no problem on a one-user system; but on an MFT system it means that a program would be constrained to run in the specific partition for which it was translated. Such programs cannot be run on an MVT system without some provision for hardware relocation.
-
Relocatable code
More recent translators produce relocatable code that contains within itself the information needed to allow the code to later be modified to run in any location in memory. Sometimes, this information is used by the operating system's loader to tailor the program to the specific memory allocation given to it on a given run. More often, however, this relocation is done by a linkage editor as part of the translation process - so the effect is the same as with absolute translators. (The advantage of relocation comes out in the ability to link together separately compiled programs and library routines, not in the ability to relocate the program at load time.)
-
Need for hardware support for relocation
Even if a program can be software relocated at load time, there is still a problem with full compaction or swapping, since either can lead to a program being moved in mid-execution. Since it is not generally feasible to find all the address references in the program (especially those created at run time), some form of hardware relocation is called for.
-
Address = base address + offset
Some machines generate all run-time addresses as the sum of a programmer-accessible base register plus an offset provided by the programmer.
Ex: IBM 360/370 family: each address is specified as the sum of a 12 bit offset plus the contents of one of 15 general registers (R1..R15).
Ex: Intel 8086/8088: each address is specified in terms of a 16 bit offset plus the contents of one of 4 segment registers dedicated to this purpose alone (CS,DS,SS,ES). (Later members of the family use a similar approach, but can do much more sophisticated address mapping to be discussed later.)
Relocation could be achieved by modifying the contents of these registers - but only if they are used in a carefully controlled way. In particular, if the programmer stores the value of a base register in a memory location temporarily, with the intention of reloading it later, and if the program is relocated before the register is reloaded, then it will be reloaded with the wrong value since the operating system will not know about the stored value. This temporary storage of pointers is hard to avoid on either of the example machines.
-
Address = os register + offset
A better approach is to do all relocation through a separate hardware register accessible only to the operating system. An example of such an approach is given below.
-
-
The Macintosh operating system uses an interesting approach to the problem of relocation.
-
Memory compaction is important on windowed systems
Windowed systems like the Mac rely heavily on dynamic allocation of memory for windows, dialog boxes, fonts and other resources, as well as regular dynamic allocation needed by the application. Without some scheme that allows for periodic memory compaction, fragmentation could become a severe problem.
-
The Macintosh OS supports two kinds of memory allocation requests:
-
Non-relocatable
Requests for a non-relocatable block return a pointer to a block that the OS will never move during compaction. The application may store as many copies of this pointer as it wants to where it wants to. The OS tries to keep all absolute blocks near one end of memory where they won't get in the way of compaction, and applications are encouraged to use non-relocatable blocks only when necessary and to allocate them early in execution.
-
Relocatable
Most requests are for a relocatable block, which the OS is allowed to move. What is returned in this case is a handle: a pointer to a single master pointer that in turn points to the block. The master pointer is updated whenever the block is moved, and the application references the data through double indirection (**p). (The master pointer itself is in a non-relocatable block, and so never moves; but since master pointers are small a supply can be allocated at one end of memory at application startup where they will be out of the way of later compaction activity.
Applications can store as many copies of the handle as they want wherever they want, but must be careful about storing a copy of the current value of the master pointer, since this may change. An exception is that an application may do what it wants to with a copy of a master pointer during any portion of program execution in which it is known that no calls to routines that can dynamically allocate memory will be made, since the OS only performs compaction when it needs to in order to satisfy an allocation request.
-
-
Memory Protection
Clearly multiple memory-resident processes must be protected from each other, just as the monitor must be. This calls for a hardware solution.
-
Fence (base) register
The notion of a fence register used to protect the monitor on a one job at a time system may be extended to a pair of registers that delimit the space the current user has access to:
-
Lower and upper limit registers
One possibility is lower and upper limit registers, with each address generated being compared to both limits to see if it is in range.
-
Base and bounds (limit) registers
Or, one can have a base and bounds register pair. Addresses generated by the process are checked to be sure they lie in the range 0..bounds. (Actually, only one check is needed since addresses are usually regarded as unsigned numbers.) Then, the user-generated address is added to the base register to yield a physical address.
Ex: In the example above, consider the 7K job in the 8K partition - addresses 4096 .. 12287, assuming it is allowed access to the full 8K.
-
With low and high limit registers, the low limit register would contain 4096 and the high limit register 12287. All addresses generated by the user would lie in this range.
-
With base and bounds registers, the base register would contain 4096 and the bounds register 8191. The user process would generate addresses in the range 0..8191 that would be mapped to 4096 .. 12287.
This latter approach will also solve the relocation problem.
-
-
-
Protection codes
Another way to protect memory is by the used of protection codes. Memory is divided up into blocks with a protection key for each block (ex. in IBM/MFT each block was 2K and the key size was 4 bits). The PSW (program status word) contained the key for a process, and this key was assigned to each block of memory that the process was using. If a process tried to access memory from a block that had a different key, the OS would cause an illegal access trap.
-
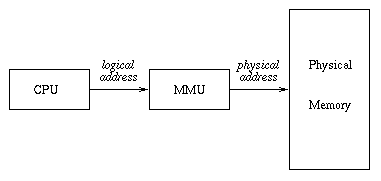
Memory management unit (MMU)
What if appropriate registers are not provided in the CPU? (e.g. most microprocessors). Does this mean that multiprogramming such a processor is hard to impossible? No, relocation can be implemented in the memory system:
-
Process in CPU sees memory 0 .. limit
If this is done, then the CPU sees memory as an array of bytes/words numbered 0 .. limit. The mapping unit converts this viewpoint into an actual physical range of addresses.
-
OS must have access to MMU registers
Of course, the operating system must have access to the mapping units registers. This can be done by treating the mapping unit as an IO device, so that the operating system can read/write its registers like any other device - but only when in kernel mode.
-